Context Management
Context management is a crucial feature in brewdata that allows the AI to maintain awareness of ongoing tasks, user preferences, and system state. This enables more efficient and coherent interactions, especially when using multiple tools or services.
Accessing Context Management Settings
Context management settings can be accessed through:
- Navigate to Settings in the brewdata interface
- Select the "Context Management" tab
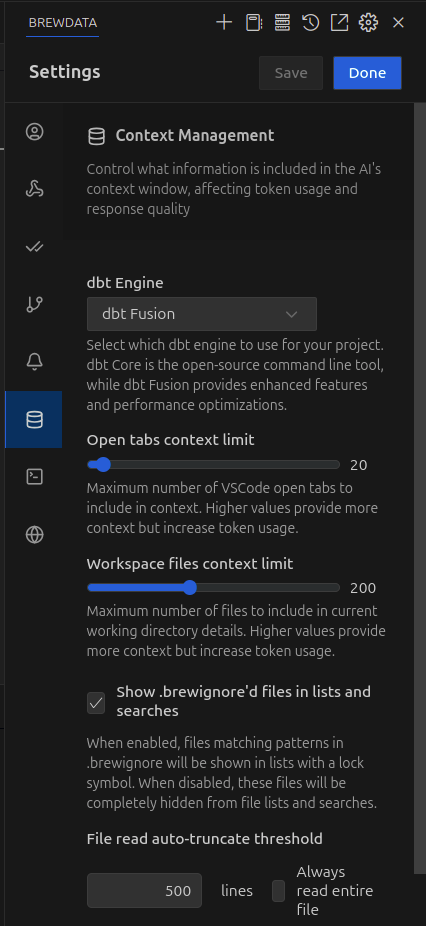
Available Configuration Options
dbt Engine Selection
You can select which dbt engine to use for your project:
- dbt Core: The open-source command line tool that provides core dbt functionality
- dbt Fusion: Enhanced version that provides additional features and performance optimizations
Prerequisites: The appropriate dbt engine (Core or Fusion) must be installed on your machine before using this feature. The AI will automatically use the selected engine when generating dbt commands during conversations.
Open Tabs Context Limit
This setting controls the maximum number of VSCode open tabs to include in the context window for the AI.
- Range: 1-20 (default: 20)
- Impact: Higher values provide more context to the AI but increase token usage, which may affect performance and costs.
- Use case: Reduce this value if you want more focused responses or need to conserve token usage. Increase it if you want the AI to be aware of more open files.
Workspace Files Context Limit
Controls the maximum number of files from your current working directory to include in the AI context.
- Range: Up to 200 (default: 200)
- Impact: Higher values provide more comprehensive project awareness but increase token usage.
- Use case: Useful to adjust based on project size - lower values for smaller projects to improve response time, higher values for complex projects where AI needs broader context.
Show .brewignore'd Files in Lists and Searches
When enabled:
- Files matching patterns in your
.brewignorewill be shown in lists with a lock symbol - When disabled, these files will be completely hidden from file lists and searches
Use case: Enable this when you need to reference ignored files occasionally but still want them visually distinguished. Disable to completely hide sensitive or irrelevant files.
File Read Auto-truncate Threshold
Determines how brewdata handles large files when including them in context:
- Lines: Specify a maximum number of lines to read per file (default: 500)
- Always read entire file: Read complete file contents regardless of size
Impact: Setting a line limit helps manage token usage for large files, while reading entire files ensures no context is missing at the cost of potentially higher token consumption.
Best Practices
- For Large Projects: Reduce workspace files limit and consider using a
.brewignorefile to exclude less relevant directories - For Token Efficiency: Set reasonable line limits for file reading and minimize open tab inclusion
- For Comprehensive Context: Increase limits but be aware of potential performance impacts
Managing .brewignore
For details on how to create and use a .brewignore file to exclude specific files from context, see the brewignore documentation.